9 Mixed models
These exercises introduce relatedness to association testing with mixed models.
9.1 Null model
The first step in an association test is to fit the null model. In addition to the AnnotatedDataFrame with phenotypes we used previously, we will need the principal components and kinship. We will use the first five PCs to adjust for ancestry.
# sample annotation
repo_path <- "https://github.com/UW-GAC/SISG_2019/raw/master"
if (!dir.exists("data")) dir.create("data")
sampfile <- "data/sample_phenotype_annotation.RData"
if (!file.exists(sampfile)) download.file(file.path(repo_path, sampfile), sampfile)
annot <- TopmedPipeline::getobj(sampfile)
library(Biobase)
head(pData(annot))## sample.id subject.id Population Population.Description sex
## 1 HG00096 HG00096 GBR British in England and Scotland M
## 2 HG00097 HG00097 GBR British in England and Scotland F
## 3 HG00099 HG00099 GBR British in England and Scotland F
## 4 HG00100 HG00100 GBR British in England and Scotland F
## 5 HG00101 HG00101 GBR British in England and Scotland M
## 6 HG00102 HG00102 GBR British in England and Scotland F
## status age height study
## 1 0 47 165.300 study_1
## 2 1 47 144.780 study_3
## 3 0 40 185.500 study_2
## 4 1 45 150.622 study_3
## 5 0 40 177.800 study_3
## 6 0 49 169.100 study_1# load the PCs
pcfile <- "data/pcs.RData"
if (!file.exists(pcfile)) download.file(file.path(repo_path, pcfile), pcfile)
pcs <- TopmedPipeline::getobj(pcfile)
pcs <- pcs[,c("sample.id", "PC1", "PC2", "PC3", "PC4", "PC5")]
head(pcs)## sample.id PC1 PC2 PC3 PC4 PC5
## 1 HG00096 -0.02098435 -0.03716014 -0.007539234 -0.004984352 -0.03920777
## 2 HG00097 -0.01929295 -0.03289496 -0.009176117 -0.005328914 -0.03297778
## 3 HG00099 -0.02042444 -0.03371227 -0.010983795 -0.004856350 -0.03208595
## 4 HG00100 -0.01970348 -0.03978044 -0.013302258 -0.004340841 -0.04208343
## 5 HG00101 -0.01959563 -0.03431033 -0.008571074 -0.002220712 -0.03260015
## 6 HG00102 -0.02041573 -0.03941142 -0.010696762 0.001506639 -0.02913023# add PCs to the sample annotation
dat <- left_join(pData(annot), pcs, by="sample.id")
pData(annot) <- dat
save(annot, file="data/sample_phenotype_pcs.RData")We create a kinship matrix from the output of pcrelate. We multiply the kinship values by 2 to get values equivalent to a GRM. This matrix is represented in R as a symmetric matrix object from the Matrix package.
kinfile <- "data/pcrelate_kinship.RData"
if (!file.exists(kinfile)) download.file(file.path(repo_path, kinfile), kinfile)
pcrel <- TopmedPipeline::getobj(kinfile)
library(GENESIS)
kinship <- pcrelateToMatrix(pcrel, scaleKin=2, verbose=FALSE)
dim(kinship)## [1] 100 100kinship[1:5,1:5]## 5 x 5 Matrix of class "dsyMatrix"
## HG00110 HG00116 HG00120 HG00128 HG00136
## HG00110 1.046618916 0.01896886 -0.01635266 -0.006769183 -0.022907033
## HG00116 0.018968859 0.92512545 0.19178400 0.013529261 -0.018774460
## HG00120 -0.016352656 0.19178400 0.96012109 -0.014849711 -0.046482113
## HG00128 -0.006769183 0.01352926 -0.01484971 0.914741469 -0.003540016
## HG00136 -0.022907033 -0.01877446 -0.04648211 -0.003540016 1.007541773We fit the null model, adding the PCs to the list of covariates, and specifying the kinship as the covariance matrix with the cov.mat argument. As before, we use study as a grouping variable.
nullmod <- fitNullModel(annot, outcome="height",
covars=c("sex", "age", "study", paste0("PC", 1:5)),
cov.mat=kinship, group.var="study", verbose=FALSE)
save(nullmod, file="data/null_mixed_model.RData")9.2 Single-variant tests
Now we can run a single-variant test, accounting for relatedness between the subjects.
library(SeqVarTools)
gdsfile <- "data/1KG_phase3_subset_chr1.gds"
if (!file.exists(gdsfile)) download.file(file.path(repo_path, gdsfile), gdsfile)
gdsfmt::showfile.gds(closeall=TRUE) # make sure file is not already open
gds <- seqOpen(gdsfile)
seqData <- SeqVarData(gds, sampleData=annot)
iterator <- SeqVarBlockIterator(seqData, verbose=FALSE)
assoc <- assocTestSingle(iterator, nullmod)## # of selected samples: 100head(assoc)## variant.id chr pos allele.index n.obs freq Score Score.SE
## 1 1 1 970546 1 100 0.015 -0.08540038 0.14196057
## 2 2 1 985900 1 100 0.045 -0.22242172 0.23151080
## 5 5 1 1472676 1 100 0.005 -0.08038064 0.08682388
## 7 7 1 2185887 1 100 0.005 0.02490900 0.07345651
## 9 9 1 2629401 1 100 0.025 0.16640007 0.18372229
## 10 10 1 2710895 1 100 0.060 0.09144953 0.27222156
## Score.Stat Score.pval
## 1 -0.6015782 0.5474550
## 2 -0.9607401 0.3366828
## 5 -0.9257895 0.3545554
## 7 0.3390986 0.7345355
## 9 0.9057152 0.3650866
## 10 0.3359379 0.7369177qqPlot(assoc$Score.pval)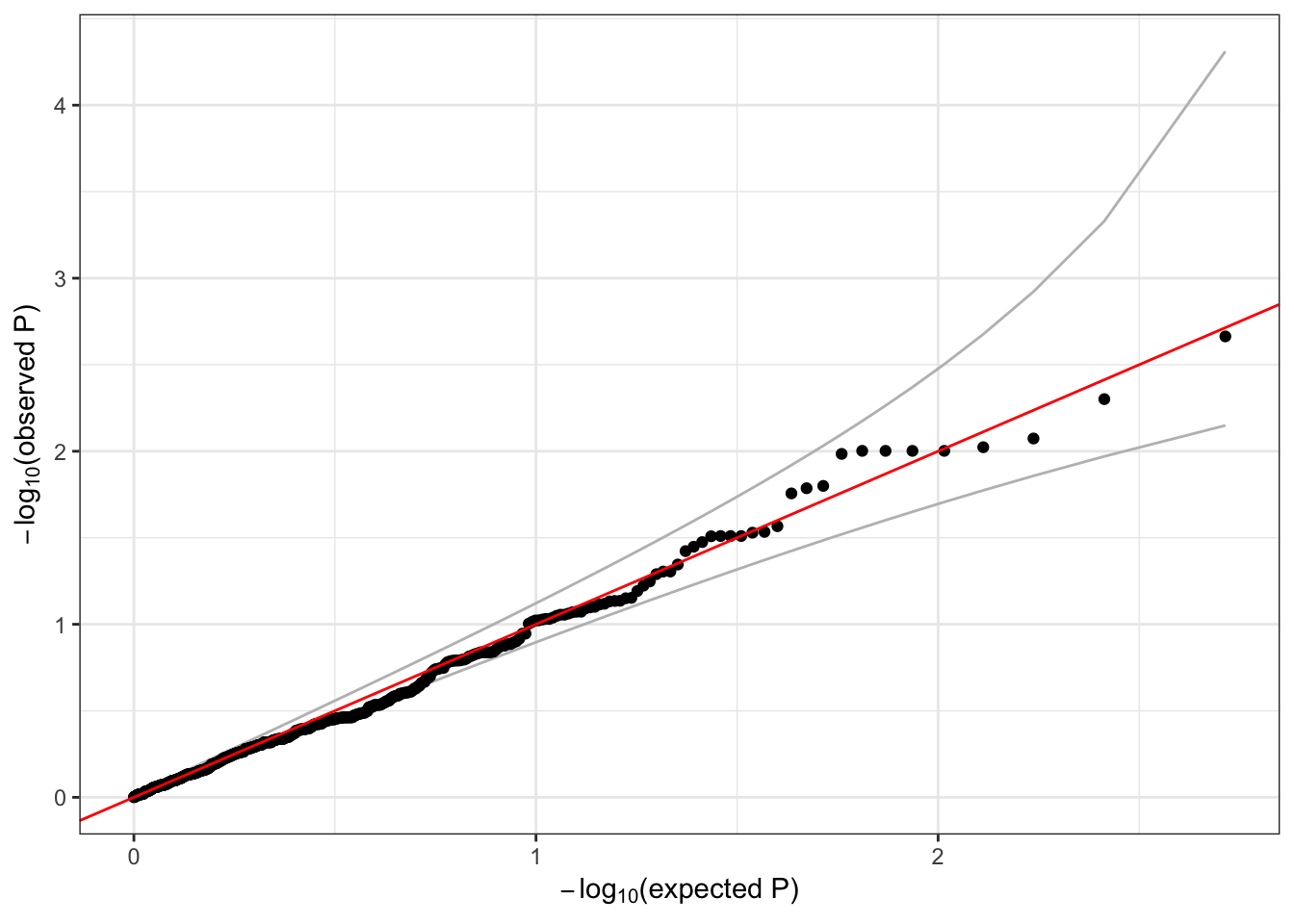
9.3 Exercise
Run a sliding window test using the mixed model and make a QQ plot.